こんにちは!
ヤマレコ代表のmatoyanです。
今週は日曜の夜から3日間、東京出張をしてきました。東京は松本と比べると暑いですねー。
東京に行くと色々な人に会えるので、インバウンドなども含めた観光業の面からのお話を伺ったり、各所で以前から問題になっている「登山道整備や救助費用を各自治体が負担しているのに、山に行ったり遭難している人が県外の方が断然に多い問題」について情報交換したり。
今起きている・今後起きそうな問題に対して、どんな対策やビジネスがあるのかを考える機会になりました。
あとは東京にはヤマレコのデータセンターもあるので、今年こそ仕事はほどほどにして色々な山に行けるように、サーバーの増強を前もってしてきました。そこで、今回はヤマレコのシステムを安定に運用するためのお仕事について記事を書いてみます。
ヤマレコのサービスは365日24時間稼働することが前提で動いています。
先日も新しく2台のサーバーを追加してきましたが、ヤマレコのデータセンターには自作のサーバーマシンが20台以上並んでいます。
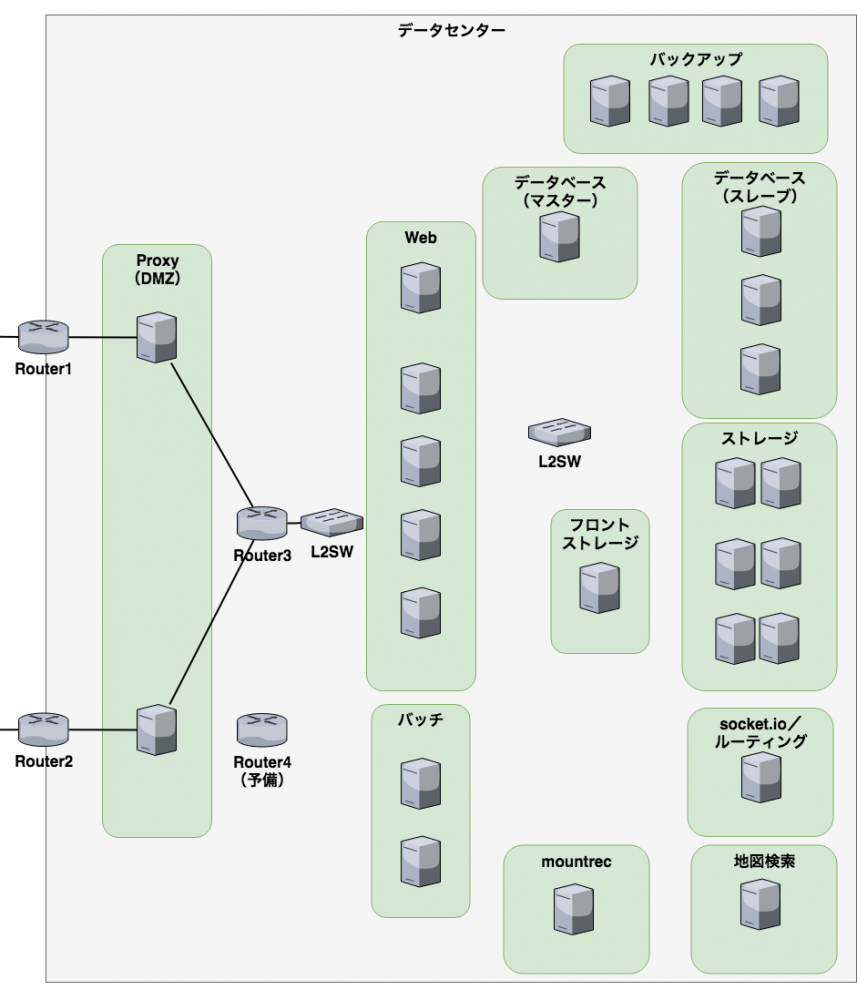
20台以上もサーバーが並んでいると、どれが壊れるかが全くわかりません。台数が増えれば増えるほど、どれか1台が故障する確率が上がっていきます。サーバー以外にもルーターやスイッチと呼ばれるネットワーク機器が壊れたり、インターネットの接続が不安定になったりする場合もあります。
上記のシステム構成図を見てもわかるように全体を2重にしたりして故障が起きても耐えられるようにしていますが、できれば故障の前兆を捉えて対処し、もし壊れてしまったら急いで復旧をする必要があります。
それらを監視するためにいくつかの方法を組み合わせています。
1.内部監視:munin
muninはオープンソースのサーバーの監視用プログラムです。実際は監視される側(munin-node)と監視する側(munin)という2種類のプログラムがあります。munin-nodeというプログラムを各マシンに入れておけば、muninというプログラムが各サーバーの状態を収集してくれます。

各サーバーで、例えばどの程度の負荷がかかっているのか、ハードディスクの状態に問題はないか、各プログラムが正常に動いているか、などを定期的に収集してグラフ化してくれます。
例えばこんな感じのグラフだと、ちょうどお昼休みの時間帯に負荷が上がっていることがわかります。

調査をする各パラメータごとに「ここからは異常」という設定ができて、その設定を超えた(上回るか、下回る)場合にメールで通知をすることができます。
監視をする人(私)のメールアドレスに送り、かつSlackという社内用のチャットにも異常が起きている通知を送ります。
例えばハードディスクが一杯になって溢れそうになったらこんな感じで通知が来ます。
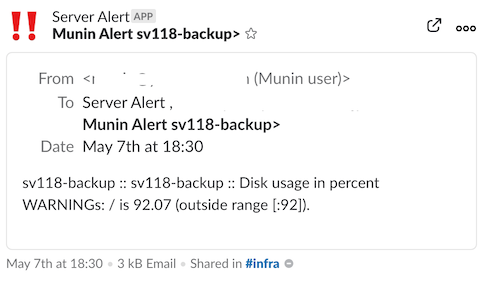
Slackのアプリをスマホに入れておくと通知が来るので、すぐに対応が必要なのか、調査が必要なのか、あとでやればいいのか、様子を見るのか判断します。
2.内部監視:NewRelic
muninではサーバーの物理的な故障や、HTTPサーバーなどのサーバー機能の障害は検知できるのですが、アプリの動作やデータベースの状況などは限定した情報しか得られません。よりアプリの内側まで踏み込んだ監視をするために、NewRelicという外部のサービスも利用しています。色々と種類があるのですが、その中でプログラムの稼働状態をより詳しく監視するAPM(Application Perfomance Monitoring)というサービスを利用しています。

Webサーバーに「エージェント」と呼ばれるプログラムを入れておくと、処理時間などを自動的に計測してくれます。さらに、PHPのプログラム・データベース・外部サービスの呼び出しなど、実際に処理に掛かった時間を細分化してくれて、どの処理に一番時間がかかっているか、特にデータベースであればどの処理(SQL文)に時間がかかっているかまで調べてくれます。
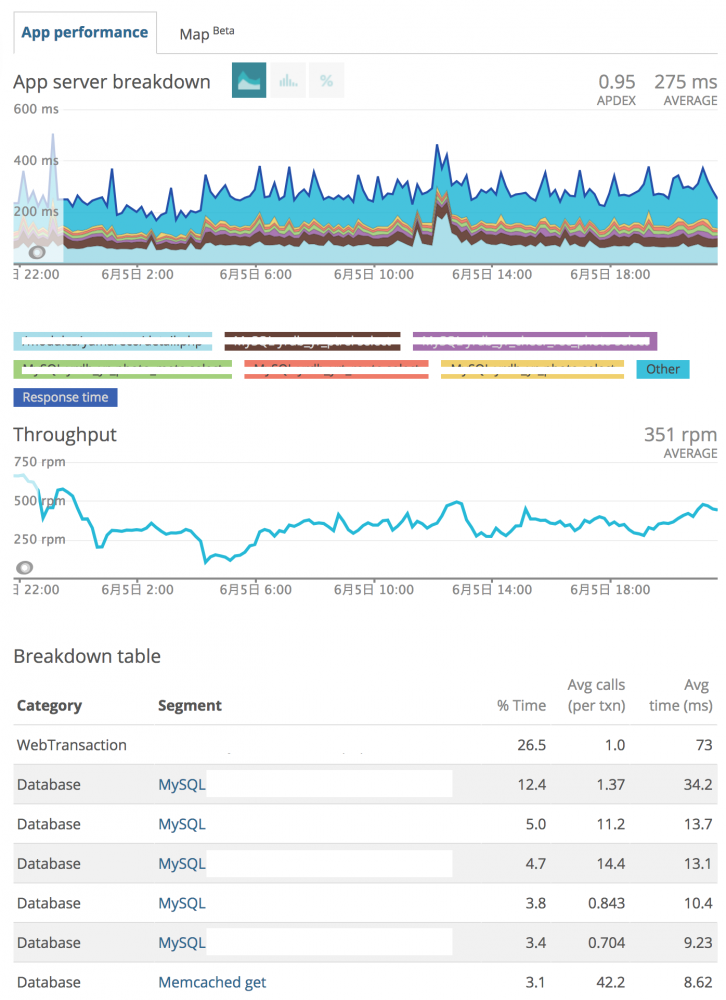
こちらは性能障害と呼ばれる「なんかサイトが重いけど原因がわからない」という時の調査のときに活躍してくれます。サーバーの台数に応じて課金があり、ヤマレコのサーバー台数では毎月数万円かかります。何も起きない場合は役に立たないことを考えると割高にも感じるのですが、過去の障害発生時に活躍した経緯もあり、いざという時の保険だと思って入っています。
3.外部からの監視
上記の2つはサーバーの内部調査なので、例えばネットワークの調子が悪いなど「外部からヤマレコにアクセスしたときに表示できない」という問題を検知できません。そのため、データセンターとは別の場所にあるサーバーから、ヤマレコのWebサイトや特定のページにアクセスして応答時間を計測しています。
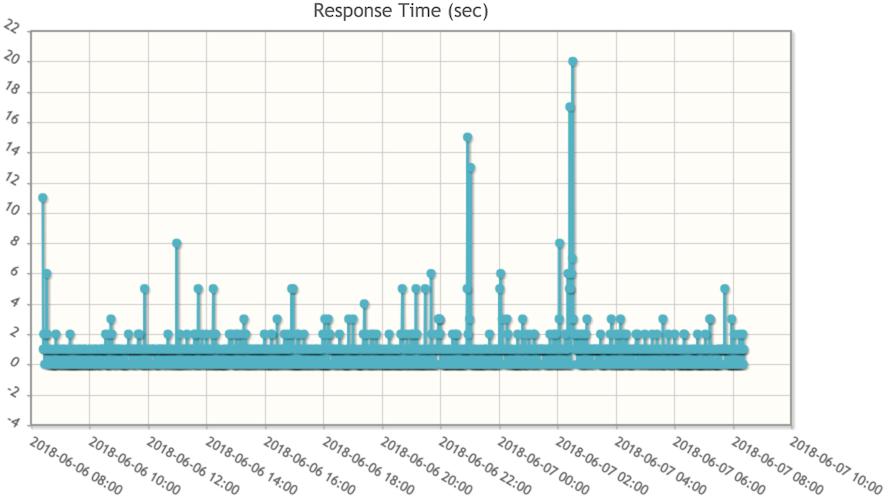
通常は応答時間を測ってグラフにするだけなのですが、応答が返ってこない場合や画面が真っ白になっているなどの異常を検知した場合は、メールとSlackの両方で警告を送ります。毎分チェックをして、応答に問題があったときに下記のような通知が来ます。

さらに5分間連続で問題を検知したときには「いよいよサーバーが落ちたのでは?」と判断して、私のスマホが鳴りはじめます。

この通知をするために、LINEでの通話呼び出しなどと同じようなVoIPでの通話通知機能を持つ専用のアプリを作りました。ちなみに通話できそうに見えますが、呼び出しをするだけのアプリなので受話器を取ってもなにも起きません。
これ以外にも、データセンターの室温監視やWebカメラによる目視もできるようになっています。
これらの3つの監視の仕組みを使い分けて、「異常が起きたこと」「異常が起きそうな状態になっていること」を迅速に認識して対応ができるようにしています。
ただ今のところ対応できるのが私だけなので、お酒を飲んで寝てる場合は対応が少し遅くなってしまうかもしれません・・・。
開発をする片手間でここまでのシステムを作ってきましたが、さすがにアプリやWeb開発と並行してサーバーの監視や増強・自動化などを進めるのは正直きついのが現状です。そこでヤマレコではこの春からインフラのエンジニアも募集を開始しました!
勤務地は長野県松本市になりますが、データセンターは関東にあるので2地域を行き来する事になります。興味を持った方は社員募集のページも見てみてください!
by matoyan

